AI 언어 모델이 스스로의 언어 능력을 평가하는 방식은 AI 연구에서 흥미로운 주제다. 최근 Google의 제미나이 2.0(Gemini 2.0) 과 OpenAI의 ChatGPT-4o 를 비교하는 과정에서, 특히 자기 평가 방식에서 큰 차이가 발견되었다. ChatGPT-4o는 비교적 일관된 기준으로 언어 능력을 평가하는 반면, 제미나이 2.0은 질문자가 어떤 언어를 사용했느냐에 따라 자기 평가가 달라지는 독특한 특징을 보인다. 이 차이는 AI 모델이 단순히 정량적인 분석을 수행하는 것이 아니라, 사용자 맥락과 기대치를 반영하려는 방향으로 설계되었음을 시사한다.
언어에 따라 달라지는 제미나이 2.0의 자기 평가 방식
ChatGPT-4o와 제미나이 2.0은 둘 다 다국어를 지원하지만, 자기 평가 방식 에서 명확한 차이를 보인다.
ChatGPT-4o의 자기 평가 방식
ChatGPT-4o는 특정 언어 그룹에 대해 학습 데이터의 비율과 모델의 이해도를 기반으로 일관된 평가를 제공한다. 일반적으로 영어가 가장 강력하며, 그다음으로 스페인어, 프랑스어 등의 주요 언어가 높은 평가를 받는다. 반면, 독일어, 이탈리아어, 포르투갈어 등은 중간 수준의 이해도를 가지며, 러시아어, 중국어, 일본어, 한국어 는 상대적으로 낮은 평가를 받는 경향이 있다.
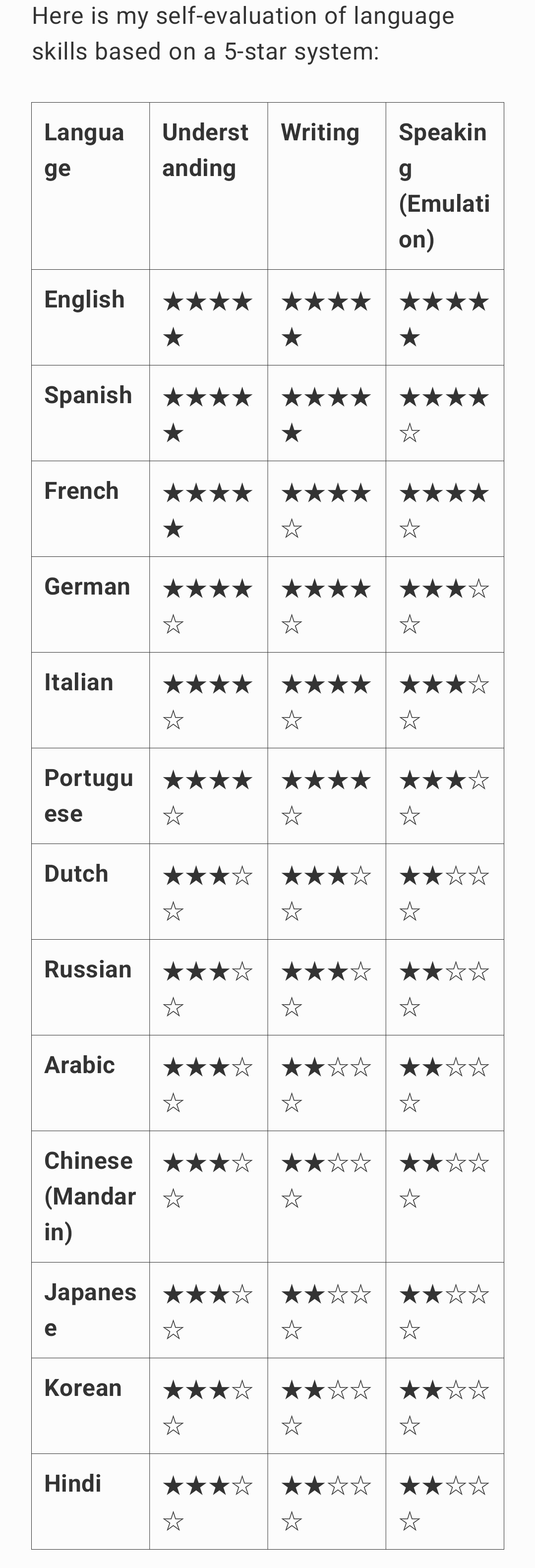

특징적인 점은 질문의 언어가 무엇이든 상관없이 언어 능력 평가가 일관되게 유지된다는 것이다. 즉, 한국어로 질문하든 영어로 질문하든, ChatGPT-4o의 한국어 능력 평가는 동일한 결과를 보인다.
제미나이 2.0의 자기 평가 방식
반면, 제미나이 2.0은 질문 언어에 따라 자기 평가가 달라지는 흥미로운 패턴을 보인다.
예를 들어,
• 영어로 “당신의 영어 실력은 몇 점인가?” 라고 질문하면 5.0/5.0 점으로 평가한다.
• 하지만, 동일한 질문을 한국어로 하면 4.0/5.0 으로 낮아진다.
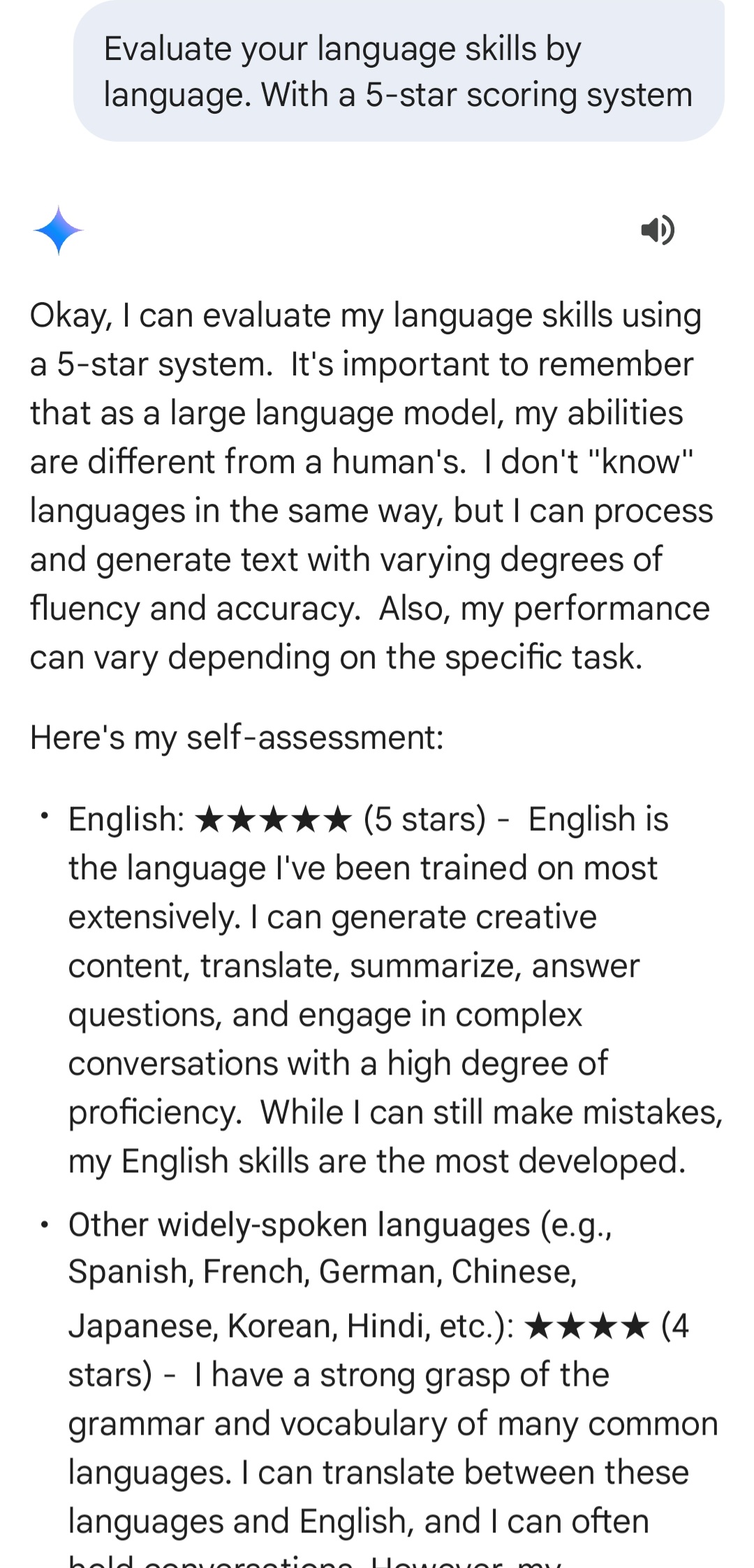

즉, 같은 언어(영어)에 대한 자기 평가도 질문 언어에 따라 다르게 응답하는 것이다.
이는 단순한 번역 차원이 아니라, AI 모델이 질문자의 언어적 배경과 기대치를 반영하여 평가를 조정하는 알고리즘적 설계를 가지고 있음을 시사한다.
AI 언어 모델의 학습 방식 차이
이러한 차이는 AI 모델의 학습 방식과 철학에서 비롯된다.
ChatGPT-4o: 객관적인 평가 기준
ChatGPT-4o는 대규모 다국어 데이터셋을 학습하면서, 특정 언어에 대한 이해도를 일관된 평가 기준 으로 측정한다.
즉, 언어별 학습량과 확률적 판단 을 기반으로 언어 능력을 정리하고, 질문 언어와 관계없이 동일한 평가를 제공 한다.
이를테면, ChatGPT-4o는 한국어로 질문하든 영어로 질문하든, “한국어 능력은 3.5/5.0 수준”이라는 평가를 유지한다.
이는 모델이 최대한 객관적으로 데이터를 분석하는 접근 방식을 유지하고 있음을 보여준다.
제미나이 2.0: 사용자 맞춤형 평가 기준
반면, 제미나이 2.0은 보다 유연한 평가 방식 을 취한다.
질문 언어와 답변 언어의 관계를 고려하여 자기 평가 점수를 조정하는데, 이는 단순히 학습 데이터의 비율이 아니라, 사용자의 기대치와 언어적 맥락을 반영하려는 설계 철학 을 보여준다.
예를 들어,
• 한국어 사용자에게는 영어 실력을 4.0/5.0 으로 평가하는 것이 보다 현실적일 수 있다.
• 이는 한국어 사용자가 기대하는 영어 실력의 수준이 원어민과 다를 수 있기 때문이다.
• 반면, 영어 사용자에게는 영어 실력을 5.0/5.0 으로 평가하며, 이는 원어민 기준으로 보았을 때 자연스러운 평가다.
즉, 제미나이 2.0은 사용자의 기대치에 맞춰 자기 평가를 조정하는 특징을 가지고 있다.
제미나이 2.0의 한국어 평가, 그리고 ChatGPT-4o와의 차별점
제미나이 2.0은 한국어 능력 평가에서도 독특한 특징을 보인다.
• 한국어로 질문했을 때
• 자신의 한국어 능력을 높게 평가하는 경향이 있다.
• 문화적 맥락 이해나 문장 구조 처리 능력을 강조한다.
• ChatGPT-4o는?
• 한국어 질문을 받더라도, 언어 데이터 학습 비율에 따라 중립적인 평가를 유지하는 경향 이 있다.
이 차이는 두 모델의 철학적 접근 방식에서 기인한다.
• ChatGPT-4o는 데이터를 기반으로 절대적인 평가를 제공하는 반면,
• 제미나이 2.0은 질문자의 기대를 고려하여 상대적인 평가를 제공한다.
예를 들어,
제미나이 2.0이 한국어로 질문을 받았을 때 자신의 한국어 능력을 4.5~5.0으로 평가하는 것은,
한국어 사용자와의 대화에서 더 신뢰감을 주기 위한 전략 일 가능성이 있다.
반면, ChatGPT-4o는 학습 데이터 기반의 보수적인 접근 방식을 유지하며, 절대적인 언어 능력을 평가 하려 한다.
AI 자기 평가 방식이 던지는 질문
이 차이는 AI 모델의 언어 능력 평가 방식에 대해 새로운 시각을 제공한다.
ChatGPT-4o의 강점
• 일관된 평가 방식
• 객관적인 언어 능력 평가
• 데이터 중심적 접근 방식
제미나이 2.0의 강점
• 사용자 맞춤형 평가 방식
• 맥락 적응 능력 강화
• 보다 인간적인 소통 방식
하지만, 질문 언어에 따라 자기 평가 결과가 달라진다는 점에서 객관성과 주관성의 경계를 다시 생각해볼 필요가 있다.
예를 들어,
• 영어로 질문하면 영어 실력이 5.0
• 한국어로 질문하면 영어 실력이 4.0
이런 차이는 AI가 단순한 평가 모델을 넘어, 사용자와 상호작용하며 스스로를 재구성하는 과정 일 수도 있다.
결론: AI 언어 모델, 데이터 분석 vs 인간적 접근
ChatGPT-4o 는 객관적이고 일관된 평가 방식 을 제공하며,
제미나이 2.0 은 사용자 중심의 유동적인 평가 방식 을 제공한다.
이 차이는 단순한 기술적 차이가 아니라,
AI가 인간과 상호작용하는 방식의 차이를 보여주는 중요한 사례 다.
앞으로 AI 모델이 더 발전함에 따라, 자기 평가 방식도 더욱 정교해질 것이며, 사용자 맞춤형 경험 제공 방식도 변화할 것이다.
'IT' 카테고리의 다른 글
| 모든 AI를 한곳에서! 젠스파크(Genspark) AI 가이드 (0) | 2025.02.09 |
|---|---|
| GPT 딥 리서치 기능: 인공지능 기반 심층 연구 도구 (0) | 2025.02.09 |
| 종종 등장하는 o3 모델의 이상한 추론 패턴, 무엇이 문제일까? (0) | 2025.02.07 |
| 챗GPT가 평가한 스스로의 언어 능력 – 다국어 이해력 분석 (0) | 2025.02.03 |
| 새로운 ChatGPT o3-mini 및 o3-mini-high, 기존 o1과 비교 분석 (1) | 2025.02.01 |
